MetadataMiner is a tool that I wrote a few years ago to allow for bulk extraction of metadata from Microsoft Office documents. The metadata in Office documents is contained in the SummaryInformation and DocumentSummaryInformation structures that we have reviewed in previous posts. The SummaryInformation structure contains the following data fields:

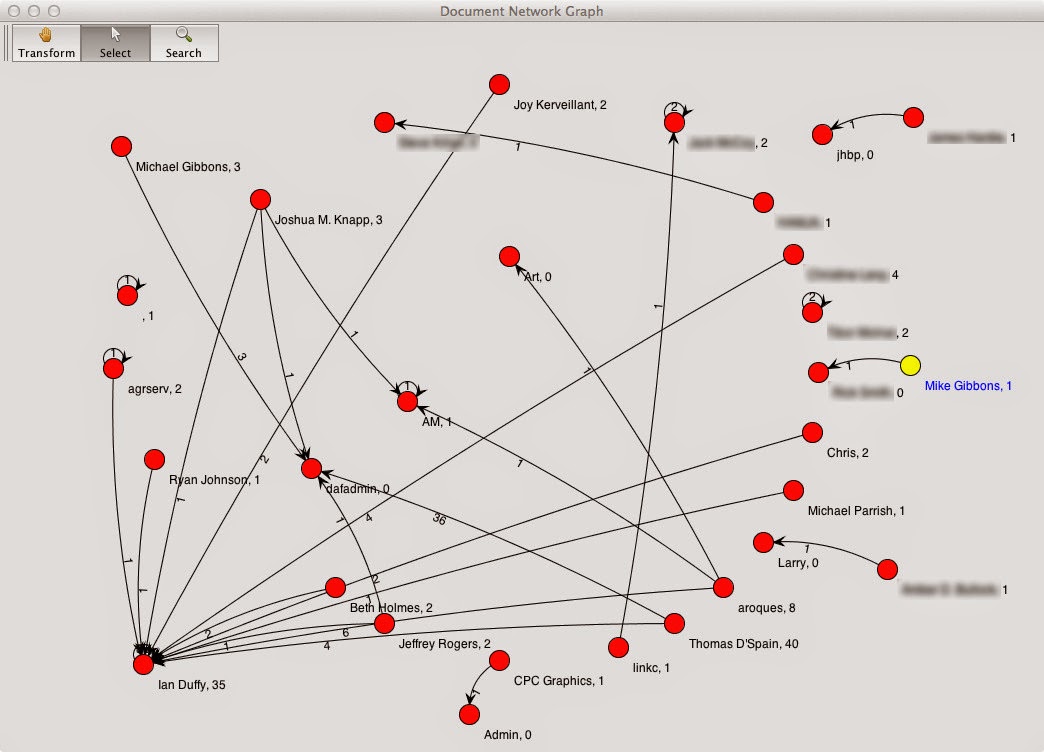 One of the new features that I have added in is the ability to visualize relationships between documents. When a document is created, the Author field and the "Last Saved By" field are set to the same value - that is, the username of the individual who first created the document. If a document is shared with another user, and that user edits the document, then that user's username is stored in the "Last Saved By" field. Thus there is a relationship there between the document's original author and the person with whom the document was shared.
One of the new features that I have added in is the ability to visualize relationships between documents. When a document is created, the Author field and the "Last Saved By" field are set to the same value - that is, the username of the individual who first created the document. If a document is shared with another user, and that user edits the document, then that user's username is stored in the "Last Saved By" field. Thus there is a relationship there between the document's original author and the person with whom the document was shared.
MetadataMiner is available on GitHub at this link. It is written in Java so you will need a Java runtime environment, (I know, I know - security issues) but you don't have to enable the browser plugin. MetadataMiner is a standalone app so you don't need to run it in your browser thus you are less prone to the security vulnerabilities that go along with the Java browser plugin. To run MetadataMiner, simply download the JAR file from GitHub (or clone the project if you prefer via the following command:
git clone https://github.com/ipduffy/MetadataMiner
Then follow the instructions on GitHub to get MetadataMiner up and running and parsing your documents. I have run it on document collections that are fairly large with no issues so I'm pretty confident in sharing this tool with the forensics community. I am still semi-actively developing this project so if you have any feedback, bug reports, or feature requests, feel free to hit me up.
- Title
- Subject
- Author
- Keywords
- Comments
- Template
- Last Saved By
- Revision Number
- Total Editing Time
- Last Print Date
- Creation Date
- Last Save Date
- Number of Pages
- Number of Words
- Number of Characters
- Thumbnail
- Creating Application
- Security
And the DocumentSummaryInformation structure contains the following data fields:
- Category
- Company
- Manager
- Hidden character count
- Line count
- Note count
MetadataMiner is a tool that can extract these fields from bulk documents. It records all of these field values into a database to allow for querying and searching. This can be useful for example, if you have a bunch of documents and want to quickly determine relationships within that batch of documents.
Say for example you have one document of interest and want to find all of the other documents that were authored or "last saved by" that same individual. MetadataMiner lets you do this quickly. You can also generate a spreadsheet of all of the metadata fields for each document and then search, sort, and filter to your heart's content. If you want to build a timeline of document activity, you can sort on the "Creation Date" field and then you can see what documents were created at what time - in sequential order.
One of the new features that I have added in is the ability to visualize relationships between documents. When a document is created, the Author field and the "Last Saved By" field are set to the same value - that is, the username of the individual who first created the document. If a document is shared with another user, and that user edits the document, then that user's username is stored in the "Last Saved By" field. Thus there is a relationship there between the document's original author and the person with whom the document was shared.MetadataMiner is available on GitHub at this link. It is written in Java so you will need a Java runtime environment, (I know, I know - security issues) but you don't have to enable the browser plugin. MetadataMiner is a standalone app so you don't need to run it in your browser thus you are less prone to the security vulnerabilities that go along with the Java browser plugin. To run MetadataMiner, simply download the JAR file from GitHub (or clone the project if you prefer via the following command:
git clone https://github.com/ipduffy/MetadataMiner
Then follow the instructions on GitHub to get MetadataMiner up and running and parsing your documents. I have run it on document collections that are fairly large with no issues so I'm pretty confident in sharing this tool with the forensics community. I am still semi-actively developing this project so if you have any feedback, bug reports, or feature requests, feel free to hit me up.